2023. 11. 07 (화) / Day 107
중복된 내용도 있다 ... 이로서 SQL부분은 끝났다.
-- 1. deptno가 20인 사람만 조회
-- 2. sal이 2000 이상인 사람만 조회
select * from emp
where deptno = 20
-- union /* 중복된 열을 한번만 표시*/
union all /* 중복에 관계 없이 모두 표시 */
select * from emp
where sal >= 2000;
select ename, ename, ename
from emp e;
select * from emp; -- 14
select * from dept; -- 4
select *
from emp, dept
order by ename; -- 56
/*
오늘 배송 주문건이 도착했습니다.
25번 상품을 아이디 momi인 고객에게 보내야 합니다.
다음 상품 목록과 고객 정보를 이용해 상품명과 배달 지역을 찾으세요
상품 목록
24번 마우스,
25번 웹카메라,
26번 모니터
고객 정보
id: onam, 지역: 평택
id: dami, 지역: 아산
id: momi, 지역: 천안
id: namsoon, 지역: 세종
*/
select deptno from emp
where ename = 'SMITH';
select * from dept
where deptno = 20;
select * from dept
where deptno in (
select deptno from emp
where ename = 'SMITH'
);
select ename, sal, e.deptno, dname
from emp e, dept d
where ename = 'SMITH'
and e.deptno = d.deptno;
select * from salgrade;
-- SMITH의 봉급은 어떤 등급인가?
select e.ename, s.grade, e.sal
from emp e, salgrade s
where
(e.sal >= s.losal and e.sal <= s.hisal)
and e.ename = 'SMITH';
-- SMITH의 급여, 급여등급, 부서이름 조회
select e.ename, e.sal, s.grade, d.dname
from emp e, dept d, salgrade s
where
e.deptno = d.deptno
and (e.sal >= s.losal and e.sal <= s.hisal)
and e.ename = 'SMITH';
select *
from emp e1, emp e2
where e1.mgr = e2.empno
and e1.ename = 'SMITH';
-- mgr이 null이면 목록에서 빠짐
select *
from emp e1, emp e2
where e1.mgr = e2.empno;
-- 왼쪽 테이블의 모든 데이터를 표시
select *
from emp e1
left outer join emp e2 on (e1.mgr = e2.empno);
select *
from emp e
--left outer join dept d on (e.deptno = d.deptno);
left outer join dept d using (deptno);
select *
from (
select rownum rnum, e1.*
from emp e1
left outer join emp e2 on (e1.mgr = e2.empno)
order by e1.empno
)
where rnum > 5 and rnum <= 10
;
select
ename,
sal,
(select empno from emp where ename = 'SMITH')
from emp;
-- Q1
-- 급여가 2000 초과인 사원의 부서이름dname, 사원번호empno, 사원명ename, 급여sal 조회
select dept.dname, emp.empno, emp.ename, emp.sal
from emp, dept
where sal > 2000
and emp.deptno = dept.deptno
;
-- Q4
-- 부서별로 가장 높은 급여를 받는 사람의 정보를 출력
select * from (
select rownum rnum, tmp.*
from (
select emp.* from emp
where deptno = 10
order by sal desc
) tmp
)
where rnum = 1
union all
select * from (
select rownum rnum, tmp.*
from (
select emp.* from emp
where deptno = 20
order by sal desc
) tmp
)
where rnum = 1
union all
select * from (
select rownum rnum, tmp.*
from (
select emp.* from emp
where deptno = 30
order by sal desc
) tmp
)
where rnum = 1
union all
select * from (
select rownum rnum, tmp.*
from (
select emp.* from emp
where deptno = 40
order by sal desc
) tmp
)
where rnum = 1
;
select *
from emp e, (
select deptno, max(sal) m
from emp
group by deptno
) t
where e.deptno = t.deptno and e.sal = t.m
;
-- Q3
-- ename의 두번째 글씨만 *로 변경해서 출력
select ename, substr(ename, 1, 1) || '*' || substr(ename, 3, length(ename)-2)
from emp;
-- Q2
-- 매니저보다 월급이 높은 사원의 ename, sal, 매니저의 ename, 매니저의 sal 조회
select e1.ename, e1.sal, e2.ename, e2.sal
from emp e1
left outer join emp e2 on (e1.mgr = e2.empno)
where e1.sal > e2.sal;
select * from emp2;
drop table emp2;
create table emp2
as select * from emp;
select * from emp2;
update emp2
set sal = sal + 100, comm = comm + 10;
update emp2
set sal = sal + 100
where deptno = 20;
select * from emp2
where job = 'CLERK';
delete emp2
where job = 'CLERK';
rollback;
insert into emp2 (empno, ename, job, mgr, hiredate, sal, comm, deptno)
values (
8000,
'최민수',
'강사',
null,
to_date('2023-11-06', 'yyyy-mm-dd'),
100,
50,
40);
select * from emp2;
insert into emp2 (
empno,
ename,
hiredate)
values (
8001,
'최민수2',
sysdate
);
commit;
rollback;
/*
DML
select, update, delete, insert
*/
drop table emp_fk;
drop table dept_fk;
create table emp_fk (
empno number(5) primary key,
ename varchar2(10),
deptno number(2) references dept_fk(deptno)
);
create table dept_fk (
deptno number(2) primary key,
dname varchar2(10) not null,
loc varchar2(10)
);
insert into emp_fk (empno, ename, deptno)
values(1, '첫번째', 10);
insert into dept_fk (deptno, dname, loc)
values(10, '휴먼', '천안');
select * from emp_fk;
select * from dept_fk;
insert into emp_fk (empno, ename, deptno)
values(225552, '두번째', 10);
delete dept_fk
where deptno = 10;
truncate table dept_fk;
drop table dept_fk;
-- 커지는 방향으로만 수정 가능
alter table emp_fk
modify empno number(6);
alter table dept_fk
drop column loc;
alter table dept_fk
add loc2 varchar2(10);
alter table dept_fk
rename column loc2 to loc;
desc emp_fk;
select * from dept_fk;
/*
DDL
create alter drop
*/
select * from dual;
select to_char(sysdate,'yy-mm-dd') from dual;
select sequence seq_emp_fk;
select seq_emp-fk.nextval from dual;
select seq_emp_fk.currval from dual;
create sequence. seq_test1 ★이것 정도만 알아두기★
start with 10000 -- 시작 숫자 ★이것 정도만 알아두기★
increment by 10 -- 10씩 증가 / 혹은 감소(음수를 쓰면 )되는 것
-- maxvalue 20000 -- 최대값
-- minvalue 10000 -- 최소값
nocycle -- 반복하지 않는 것(기본값이다. 안써도 된다.)
-- cycle --
select seq_test1.nexval from dual;
select seq_test1.curval from dual;
insert into emp_fk (empno, ename, deptno)
values (seq_emp_fk.nexval,'민수4',10)
select * from emp_fk;
drop index idx_emp;
-- index는 미리 정렬해둠
-- where 나 order by에서 활용한다.
create index idx_emp on emp(ename); --asc 생략됨);
--create index idx_emp_ename_desc on eno(ename desc);
select * from emp
order by ename;
select * from emp
where empno =7900;
정규화(Normalization)란?
정규화는 이상현상이 있는 릴레이션을 분해하여 이상현상을 없애는 과정이다. 이상현상이 존재하는 릴레이션을 분해하여 여러 개의 릴레이션을 생성하게 된다. 이를 단계별로 구분하여 정규형이 높아질수록 이상현상은 줄어들게 된다.
정규화의 장점
- 데이터베이스 변경 시 이상 현상(Anomaly)을 제거할 수 있다.
- 정규화된 데이터베이스 구조에서는 새로운 데이터 형의 추가로 인한 확장 시, 그 구조를 변경하지 않아도 되거나 일부만 변경해도 된다.
- 데이터베이스와 연동된 응용 프로그램에 최소한의 영향만을 미치게 되어 응용프로그램의 생명을 연장시킨다.
정규화의 단점
- 릴레이션의 분해로 인해 릴레이션 간의 JOIN연산이 많아진다.
- 질의에 대한 응답 시간이 느려질 수도 있다. 데이터의 중복 속성을 제거하고 결정자에 의해 동일한 의미의 일반 속성이 하나의 테이블로 집약되므로 한 테이블의 데이터 용량이 최소화되는 효과가 있다.
- 따라서 데이터를 처리할 때 속도가 빨라질 수도 있고 느려질 수도 있다.
- 만약 조인이 많이 발생하여 성능 저하가 나타나면 반정규화(De-normalization)를 적용할 수도 있다.
이상현상이란?
- 삽입 이상(Insertion Anomaly) : 튜플 삽입 시 특정 속성에 해당하는 값이 없어 NULL을 입력해야 하는 현상
- 삭제 이상(Deletion Anomaly) : 튜플 삭제 시 같이 저장된 다른 정보까지 연쇄적으로 삭제되는 현상
- 갱신 이상(Update Anomaly) : 튜플 갱신 시 중복된 데이터의 일부만 갱신되어 일어나는 데이터 불일치 현상
함수 종속성(FD : Functional Dependency)이란?
- 함수 종속성은 어떤 속성 A의 값을 알면 다른 속성 B의 값이 유일하게 정해지는 관계를 종속성이라고 한다.
- A->B로 표기하며 A를 B의 결정자(Determinant)라고 한다.
- A->B이면 A는 B를 결정한다(Determine) 한다고 하고, B는 A에 종속한다(Dependent)라고 한다.
함수 종속성 다이어그램(FD Diagram)
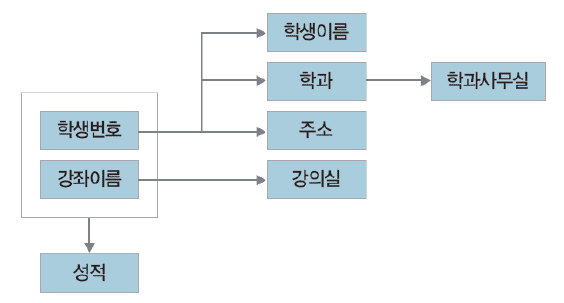
- 릴레이션의 속성 : 직사각형
- 속성 간의 함수 종속성 : 화살표
- 복합 속성 : 직사각형으로 묶음
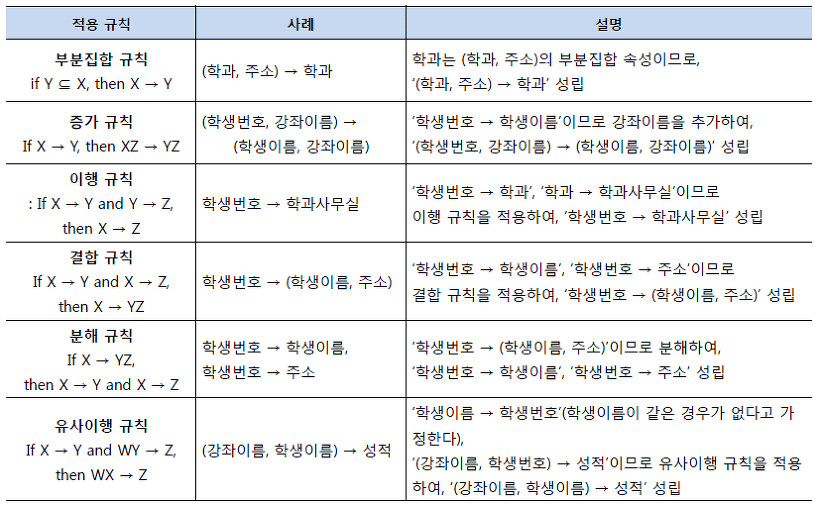
함수 종속성 규칙
제1 정규형 (1NF)
제1 정규형은 다음과 같은 규칙들을 만족해야 한다.
1. 각 컬럼이 하나의 속성만을 가져야 한다.
2. 하나의 컬럼은 같은 종류나 타입(type)의 값을 가져야 한다.
3. 각 컬럼이 유일한(unique) 이름을 가져야 한다.
4. 칼럼의 순서가 상관없어야 한다.
조금 복잡해보이지만, 간단하게 예시를 들면 이해가 빠르다. 아래 테이블을 살펴보자.
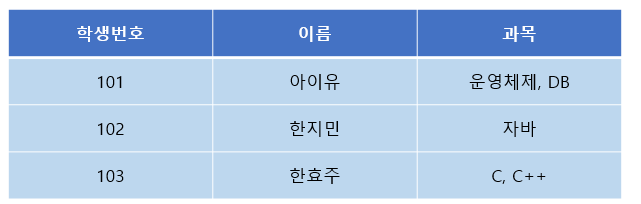
- 각 컬럼이 하나의 값(속성)만을 가져야 한다. -> 불만족! 하나의 칼럼(과목)에 두 개의 값을 가짐
- 하나의 컬럼은 같은 종류나 타입(type)의 값을 가져야 한다. -> 만족
- 각 컬럼이 유일한(unique) 이름을 가져야 한다. -> 만족
- 칼럼의 순서가 상관없어야 한다. -> 만족
1번 규칙을 불만족하므로 이를 고치기 위해서는 아래와 같이 분해하면 된다.
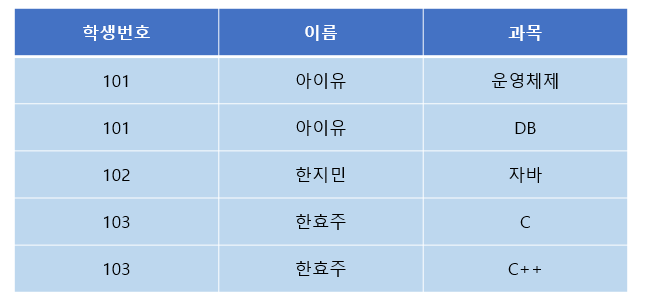
위와 같이 각 칼럼이 원자 값을 갖도록 테이블을 분해하면 1 정규형을 만족하게 바꿀 수 있다.
제2 정규형 (2NF)
제2 정규형은 다음과 같은 규칙을 만족해야 한다.
1. 1정규형을 만족해야 한다.
2. 모든 컬럼이 부분적 종속(Partial Dependency)이 없어야 한다. == 모든 칼럼이 완전 함수 종속을 만족해야 한다.
부분적 종속이란 기본키 중에 특정 컬럼에만 종속되는 것이다.
완전 함수 종속이란 기본키의 부분집합이 결정자가 되어선 안된다는 것이다. ( 비슷한 말이다 )
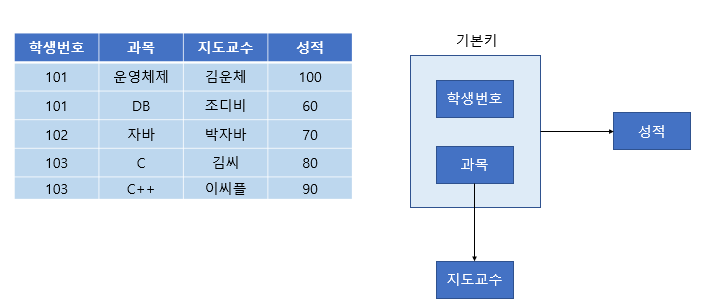
위와 같은 테이블과 FD 다이어그램을 보자.
성적의 특정 값을 알기 위해서는 학생 번호+과목이 있어야 한다. (ex : 102번의 자바 성적 70 )
하지만 특정 과목의 지도교수는 과목명만 알면 지도교수가 누군지 알 수 있다. (ex : 자바의 지도교수 박자바)
위 테이블에서 기본키는 (학생 번호, 과목)으로 복합키이다.
그런데 이때 지도교수 칼럼은 (학생 번호, 과목)에 종속되지 않고 (과목) 에만 종속되는 부분적 종속이다.
따라서 제2 정규화를 만족하지 않으므로 아래와 같이 분해해야 한다.
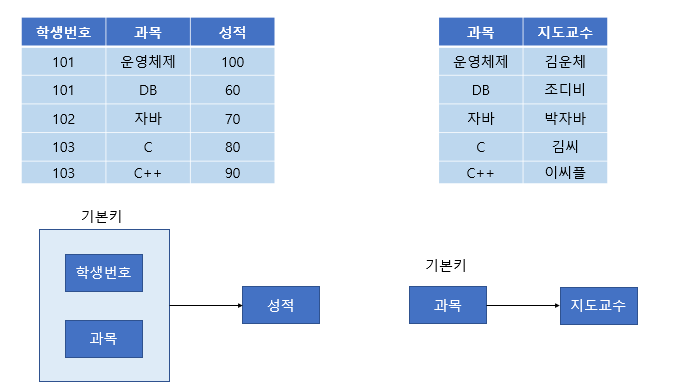
위와 같이 분해하면 제2 정규형을 만족한다.
제3 정규형 (3NF)
제3 정규형은 다음과 같은 규칙을 만족해야 한다.
1. 2 정규형을 만족해야 한다.
2. 기본키를 제외한 속성들 간의 이행 종속성 (Transitive Dependency)이 없어야 한다.
이행 종속성이란 A->B, B->C 일 때 A->C 가 성립하면 이행 종속이라고 한다.
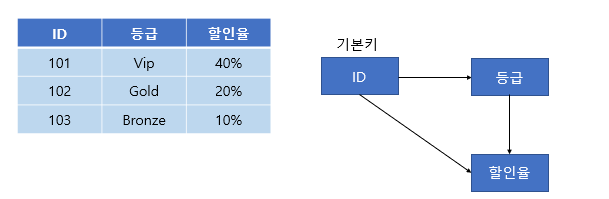
위와 같은 테이블을 보자. ID를 알면 등급을 알 수 있다. 등급을 알면 할인율을 알 수 있다. 따라서 ID를 알면 할인율을 알 수 있다. 따라서 이행 종속성이 존재하므로 제 3 정규형을 만족하지 않는다.
3정규형을 만족하기 위해서는 아래와 같이 분해해야 한다.
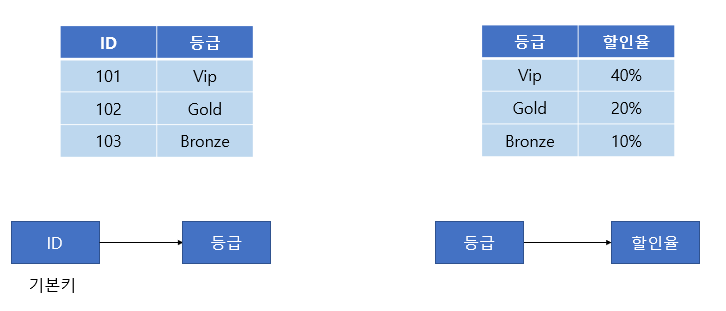
위와 같이 분해하면 제 3정규형을 만족한다.
BCNF (Boyce-Codd Normal Form)
BCNF는 제 3정규형을 좀 더 강화한 버전으로 다음과 같은 규칙을 만족해야 한다.
1. 3정규형을 만족해야 한다.
2. 모든 결정자가 후보키 집합에 속해야 한다.
모든 결정자가 후보키 집합에 속해야 한다는 뜻은, 후보키 집합에 없는 칼럼이 결정자가 되어서는 안 된다는 뜻이다.
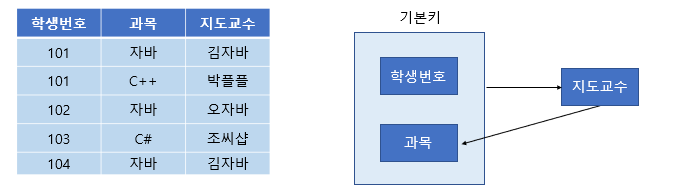
위와 같은 테이블을 보자. (학생 번호, 과목)이 기본키로 지도교수를 알 수 있다. 하지만 같은 과목을 다른 교수가 가르칠 수도 있어서 과목-> 지도교수 종속은 성립하지 않는다. 하지만 지도교수가 어떤 과목을 가르치는지는 알 수 있으므로 지도교수-> 과목 종속이 성립한다.
이처럼 후보키 집합이 아닌 칼럼이 결정자가 되어버린 상황을 BCNF를 만족하지 않는다고 한다.
(참고로 위 테이블은 제3 정규형까지는 만족하는 테이블이다 )
BCNF를 만족하기 위해서는 아래와 같이 분해하면 된다.
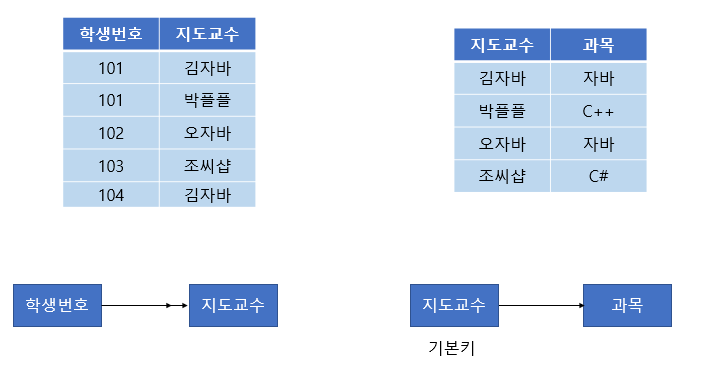
참고로 위에서 학생 번호와 지도교수는 다치 종속성이 발생하게 되는데, 이는 제4 정규형에서 다뤄진다.
제4 정규형 이상~
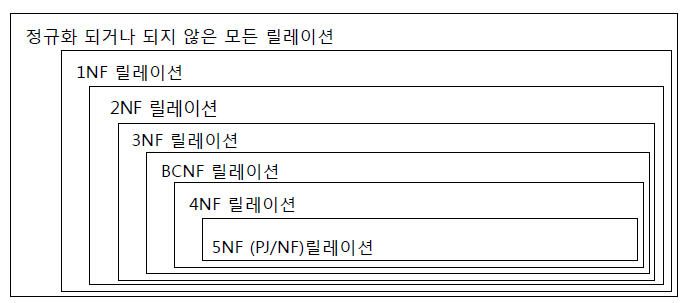
보통 정규화는 BCNF 까지만 하는 경우가 많다. 그 이상 정규화를 하면 정규화의 단점이 나타날 수도 있다.
제4 정규형(4NF)
제4 정규형은 다음과 같은 규칙을 만족해야 한다.
1. BCNF를 만족해야 한다.
2. 다치 종속(Multi-valued Dependency)이 없어야 한다.
여기서 다치 종속이란 다음과 같은 조건들을 만족할 때를 뜻한다.
1. A->B 일 때 하나의 A값에 여러 개의 B값이 존재하면 다치 종속성을 가진다고 하고 A↠B라고 표시한다
2. 최소 3개의 칼럼이 존재한다.
3. R(A, B, C)가 있을 때 A와 B 사이에 다치 종속성이 있을 때 B와 C가 독립적이다.
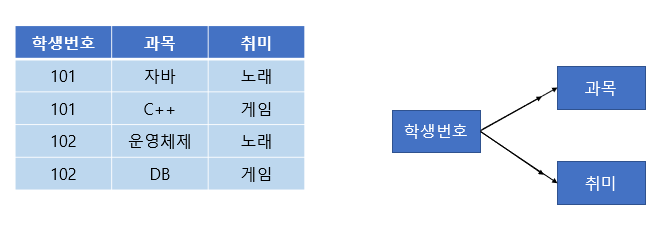
위와 같은 테이블을 보자. 101번 학생은 자바와 C++ 과목을 수강하고, 노래와 게임을 취미로 가진다.
이렇게 되면 학생 번호 하나에 과목 여러 개와 취미 여러 개가 종속된다. 이런 경우 학생 번호를 토대로 값을 조회하면 아래와 같이 중복이 발생하게 된다.
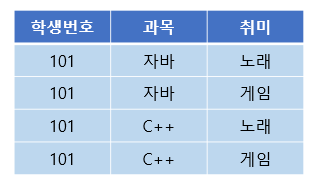
과목과 취미는 관계가 없는 독립적인 관계이다. 하지만 같은 테이블의 학생 번호라는 칼럼에 다치 종속되어버려 중복이 발생하는 문제가 생겼다.
4NF를 만족하기 위해서는 아래와 같이 분해하면 된다.
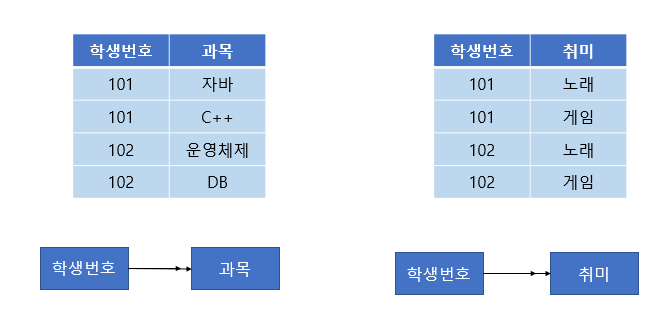
위 2개의 테이블은 여전히 다치 종속성을 가지지만, 2개 이상의 칼럼이 하나의 칼럼에 다치 종속되지는 않기 때문에 제4 정규형을 만족한다.
제5 정규형(5NF)
제5 정규형은 중복을 제거하기 위해 분해할 수 있을 만큼 전부 분해하는 것이다. 이러한 5NF는 Project Join Normal Form(PJNF)라고도 불린다. 이러한 제 5정규형은 다음과 같은 규칙을 만족해야 한다.
1. 4NF를 만족해야 한다.
2. 조인 종속(Join dependency)이 없어야 한다.
3. 조인 연산을 했을 때 손실이 없어야 한다.
조인 종속은 다치 종속의 좀 더 일반화된 형태이다. 만약 하나의 릴레이션을 여러 개의 릴레이션으로 무손실 분해했다가 다시 결합할 수 있다면 조인 종속이라고 한다.
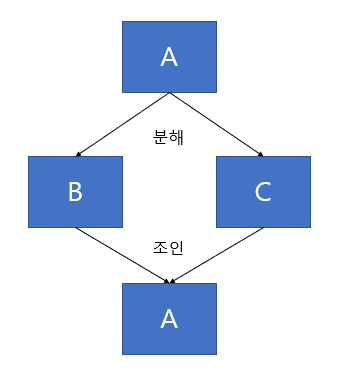
예를 들어 A라는 릴레이션을 B와 C로 분해했다가 다시 조인했을 때 그대로 A가 된다면, A는 조인 종속성이 있다고 한다.
제5 정규형의 경우 예시를 들기 복잡하기 때문에 생략하겠다.
일반적으로 현실의 데이터베이스에서는 5 정규형을 사용하지 않는다.
조인 종속을 제거한다. "
5NF는 다음을 만족해야 한다.
- 4NF를 만족해야 한다.
- 더 이상 비손실 분해를 할 수 없어야 한다.
💡 조인 종속 (Joint dependency)
하나의 릴레이션을 여러개의 릴레이션으로 분해하였다가, 다시 조인했을 때 데이터 손실이 없고 필요없는 데이터가 생기는 것을 말한다. 조인 종속성은 다치 종속의 개념을 더 일반화한 것이다.
예제
위의 4NF 테이블에 대해 조인 연산을 수행하면 다음과 같은 결과가 나온다.

위의 결과를 보면 제 4정규화를 수행하기 전 데이터와 다른 것을 알 수 있다.
데이터 손실은 없지만 필요없는 데이터가 추가적으로 생겼으므로 5NF를 만족하지 않는다.
제 5정규화를 통해 다음과 같이 분리할 수 있다.
